STGYのアーキテクチャ
本記事では、STGYの実装について解説する。STGYは開発者がTypeScriptとNode.jsの勉強をするために作ったシステムであり、バックエンドもフロントエンドも教科書的な設計と実装を目指している。SNSのシステムではあるが、多くの案件でこの設計や実装を流用できることを期待している。
アーキテクチャ
STGYのアーキテクチャを以下の図に示す。ざっくり言うと、最下層にDBがあり、それを扱うビジネスロジック層としてバックエンドサーバがあり、そのエンドポイントを叩くユーザインターフェイス層があるという、3層構造だ。オンプレミスでもクラウドでも運用しやすいように配慮している。
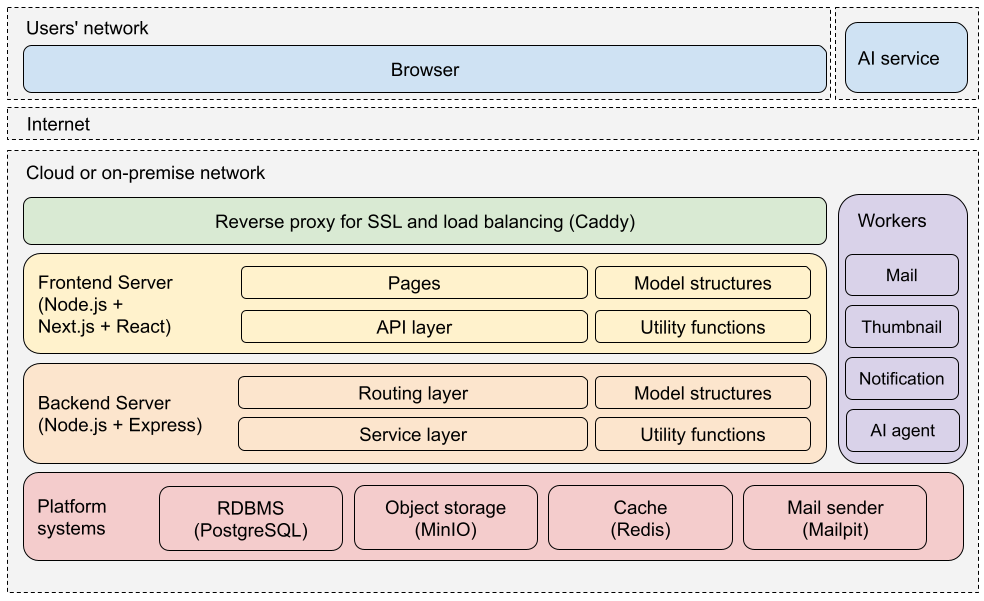
Webシステムのフロントエンドの記述言語はJavaScript一択であり、ある程度の規模になるとTypeScript化して保守性を高めることが必須になる。そして、バックエンドも同じ言語で書きたいので、Node.js上でTypeScriptを動かすことにした。バックエンドのフレームワークにはExpressを使い、フロントエンドのフレームワークにはNext.jsとReactを使う。
DBサーバにはPostgreSQLを採用した。MySQLでも別に良かったのだが、管理系のコマンドが使いやすいのでPostgreSQLにした。キャッシュにはRedis、ファイルストレージにはMinIO、メールサーバにはMailpit、リバースプロクシにはCaddyを使うことにした。いずれのサブシステムもAWS上でマネージドシステムが利用できる。PostgreSQLにはRDSが、RedisにはElastic Cacheが、MinIOにはS3が、MailpitにはSESが、CaddyにはALBが対応する。
バックエンドのサービスと分離したワーカープロセスがいくつかある。それらは、バックエンドのリクエストの中で実行するには時間がかかりすぎる処理を担当する。各ワーカーはRedisにキューイングされたタスクを逐次実行していく。メールの送信、サムネイルの作成、ユーザへの通知の作成、そしてAIエージェントの駆動がそれにあたる。
フロントエンドのNext.js単体ではHTTPS(SSL)の機能がないため、実運用では前段にリバースプロキシを置いてHTTPS化をするのが必須になる。また、Next.js単体はシングルスレッドでしか動かないので、CPUコア数分のNext.jsを立てるなり、複数台のホスト使うなりして処理性能を上げていくことになるが、その際のロードバランサとしても前段のリバースプロキシが活躍する。さらにその前段にコンテンツのキャッシュ配信を担うCDN層を置くこともでき、AWS上ではCloudFrontがそれを担うが、今回は必要ないだろう。
上掲のアーキテクチャ図ではフロントエンドがホスティングサイト内で動作するように描かれているが、実際にはフロントエンドのほとんどの機能はクライアントサイドレンダリングで実現されていて、Next.jsはJavaScriptをクライアントに送る仕事しかしない。ブラウザ上で動作するJavaScriptコードがバックエンドのエンドポイントを叩きながら処理を進めるという風に捉えた方が適切である。したがって、バックエンドのエンドポイントには悪意のあるリクエストが来ることを前提として設計および実装をする必要がある。
最小構成
AWS上で運用するとして、全部一台のEC2に置く最小構成を考えてみる。EC2のt4g.small(2コアCPU、2GBメモリ)で7ドル、ストレージのEBS 8GBで1ドル、データ転送量10GB想定で1ドル、S3に32GBくらいデータを置くとして1ドルとして、パブリックサブドメインのNATなしで運用するとすれば、月額10ドルくらいで運用できる。アクティブユーザ数が1000人程度の内輪で使うSNSとして運用するなら、それで十分だろう。
アクティブユーザ数が1万人以下の中規模サイトまでなら、VPSでも十分運用できるし、その方がコスパが良い。例えば、さくらVPSの4GBプラン(4コアCPU、4GBメモリ、SSD 200GB)であれば、月額3227円で、初期費用4400円足せばSSDを400GBに拡張できる。PostgreSQLやMinIOやその他全てのサービスを同一ホストで動かしても1台で問題なく動く。EC2のt4g.smallよりはずっと高性能で、ストレージもずっと大きいので、安心して運用できる。何より、固定料金なので、突然人気が出たり乱用されたりしても大幅な損失にならないのが良い。
商用サービスとして真面目にやるなら、やはりAWSなどのクラウドで運用して、各サーバを別インスタンスに配置して、サブネットを切って、NATを置いて、監視やレプリケーションやバックアップの仕組みを整えることになるだろう。可用性の要件があるなら、アベイラビリティゾーンをまたがったデプロイとデータレプリケーションを設定するだろう。その場合の費用は結構なものになるだろうが、そこまでサービスが育ったなら、何らかの方法で回収できることだろう。
必要なコンピューティングリソース
平均的なアクティブユーザの毎日の行動を次のように見積もる。各人は、10回の投稿リスト画面表示と、10回の投稿詳細表示と、5回のユーザリスト画面表示と、5回のユーザ詳細画面表示をする。また、500文字の記事を2回投稿して、1個の画像をアップロードする。画像は500KB、サムネイル画像は100KBとする。投稿リスト画面の中には20個の記事のスニペットが含まれ、そこには平均10個のサムネイルが含まれる。
DBの検索系のクエリは、検索とデータ読み出しを総合して、リスト表示も詳細表示も同程度の負荷とみなす。それが1ユーザ1日あたり10+10+5+5=30回投げられる。つまり、QPSは1万ユーザあたり30/86400*10000=3.472である。ピーク時にはその3倍の10QPS程度が来ると想定される。更新系のQPSは1万ユーザあたり2/86400*10000=0.23であり、ピーク時にはその3倍の0.7QPS程度が来ると想定される。イイネを入れると1QPSくらいだろうか。
画像に関しては、1ユーザ1日あたり、一覧表示でのサムネイル10*20=200個と、投稿詳細表での元画像5個のダウンロードが行われる。サムネイルはキャッシュが利くので、実際の転送数は100個とする。100*100KBで、転送量は10MBとなる。元画像は5*500KBで、2.5MBとなる。アバター画像についてはほとんどキャッシュが利くということにして計上しない。つまり、転送量は合計12.5MBである。1万ユーザあたり125GBであり、ビット数で換算すると1000Gbであり、必要スループットは11.57Mbpsとなる。ピークタイムはその3倍の35Mbps程度が来ると想定される。
つまるところ、DBの負荷は1万ユーザでは余裕があるし、10万ユーザでも耐えそうだが、ネットワーク転送量が先に問題になるだろう。例えばAWSなら0.114ドル/GBなので、1万ユーザで1日あたり8.55ドルかかる。さくらVPSは定額でネットワーク量もコミコミだが、100Mbpsの共用回線なので、10Mbpsとかで利用制限がかかってもおかしくない。ゆえに、画像配信に関しては1万ユーザに至る前にCDNを導入する必要があるだろう。
開発の進め方
一連の連載で述べるアーキテクチャは、水平分散(=スケールアウト)には手を出さず、その手前まで最適化する。すなわち、ホストマシン1台で運用できる状態から始めて、DBサーバやストレージサーバを分割して運用し、それらのレプリケーションで負荷分散を図るところまでは、同一の実装で対応できるようにする。水平分散をしないスケールアップ戦略だけでは、10万ユーザあたりで限界を迎えるだろう。そこまで成長できたならサービスとしては成功の部類に入るだろう。
いきなり100万ユーザを捌けるシステムを運用するのは現実的ではない。多大な初期投資をしてもそこまで成長する保証はどこにもないからだ。大規模サイトの開発や運用に必要なスキルセットを持つ人材をいきなり獲得するのも難しい。それよりは、頑張れば10万ユーザを捌ける実装をして、比較的少ない初期投資で運用を開始し、実運用と改良を続けて各人員が経験を詰むべきだ。10万ユーザに至るまでの猶予期間で、システムの課題を洗い出し、それに基づいたスケールアウト戦略を編み出して、実施するのだ。システムがスケールするだけではだめで、開発体制や運用体制がそれについていけるように組織をスケールさせねばならない。
今回の目的である「自身のフルスタック化」を達成するためには、100万人のユーザは必要ない。エンドユーザ相手の開発経験と運用経験を詰むだけなら、ユーザは1000人も居れば十分だ。まずは10万ユーザに耐える単純かつ堅牢なバックエンドを作り上げた上で、10万ユーザを獲得し得るUXを追求したい。
AIを駆使する開発という観点では、仕様をできるだけ詳しく記録しておくことが望ましい。スペック駆動開発などと言われるが、仕様をAIに読ませて、システムのプロトタイプを生成させて、それを修正していくという開発方式がある。必要十分な粒度で仕様を定義しておくと、生成されるプロトタイプの精度が上がり、修正に必要なコストが最小化する。今回は、このブログがまさに仕様定義になっている。この連載を読み込ませるだけで、Fakebookとほぼ同じシステムが生成されることを目標として、記事を執筆していく。現状のAIモデルは一般的な開発技法については人間より詳しい知識を持っているが、個々のドメインの知識は必ずしもそうではない。そこで、ある程度経験のある私の知識を入力することで、その補填ができる。
AIにとって自明な一般知識と、AIが知らなそうな知識を分けて考え、後者について詳述するのが重要だ。AIがドメイン特化の知識において比較的不得手だと書いたが、それよりも不得手というか、原理的に不可能なのは、利用者が何を達成したいかという要件を予測することである。利用者の情報は学習データに無いのだから当然だ。よって、何がやりたいのかを明確化することこそが重要になる。
Next: STGYのインストール