STGYの主要クエリ分析
本記事では、STGYの運用上でデータベースに発行されるクエリについて分析する。SQLの具体例を示し、その計算量を解析し、実際の実行計画を見て確認する。
最も単純な例
全ての投稿の中から最新20件を取り出す処理を考える。以下のクエリは実際には使われてないが、説明のための単純化したものを紹介する。デフォルトでは返信以外の投稿を一覧するため、reply_toがNULLであるという条件をつける。
SELECT p.id, p.owned_by, p.reply_to, p.allow_likes, p.allow_replies, p.updated_at FROM posts p WHERE reply_to IS NULL ORDER BY p.id DESC OFFSET 0 LIMIT 20;
postsテーブルには、reply_toがNULLのレコードだけを対象としたIDの部分インデックスが設けられているため、そのインデックスを引くだけで処理が完了する。全ての投稿数をPと置くと、計算量はO(log(P))で済む。これは、Pが莫大になっても性能に問題が出ないことを意味している。
PostgreSQLでは、クエリごとの実行計画をEXPLAIN文で調べることができる。以下の出力が得られる。インデックスを使って済むと言っている。推定3024件のレコードを持つインデックスを逆向きに操作して、20件がヒットした段階で処理を打ち切ることが示唆されている。つまりめちゃくちゃ効率的に動くということだ。
Limit (cost=0.29..2.61 rows=20 width=34) -> Index Scan Backward using idx_posts_root_id on posts p (cost=0.29..3512.64 rows=30210 width=34)
listPosts
実運用上は、各投稿の著者のユーザIDを名前に解決したり、各投稿につけられたタグ情報を結果に含めるために、別のテーブルをJOINすることになる。それを実装しているのが、バックエンドのpostsService.listPostsメソッドだ。reply_toがNULLであるという条件をつけると、実際のクエリは以下のものになる。
SELECT
p.id, p.snippet, p.owned_by, p.reply_to,
p.allow_likes, p.allow_replies, p.updated_at,
u.nickname AS owner_nickname, pu.nickname AS reply_to_owner_nickname,
ARRAY(SELECT pt2.name FROM post_tags pt2
WHERE pt2.post_id = p.id ORDER BY pt2.name) AS tags
FROM posts p
JOIN users u ON p.owned_by = u.id
LEFT JOIN posts parent_post ON p.reply_to = parent_post.id
LEFT JOIN users pu ON parent_post.owned_by = pu.id
WHERE p.reply_to IS NULL
ORDER BY p.id DESC OFFSET 0 LIMIT 20;最も単純な例と同様にインデックスが使われて、結果を返却するはずだ。その過程で、post_tagsテーブルとusersテーブルを結合している。タグに関しては返却の各行に対応して投稿IDが一致するタグをサブクエリで調べて取得して埋め込んでいる。ユーザ名に関しては、owned_byのIDをユーザ名に解決するためと、reply_toの投稿のowned_byのIDをユーザ名に解決するために、2回に分けてJOINしている。
これの計算量を考えよう。全ユーザ数をUと置き、全投稿数をPと置く。タグの数はおそらく投稿数の1%くらいの数になるだろうが、Pに比例するのでPとして扱う。まず、該当の投稿のリストを得るのに、インデックスが利けば、O(log(P))+O(20)の計算量がかかる。20は定数なので消えて、O(log(P))になる。そして、ヒットした20件の各々に対し、タグとユーザ名を解決する。インデックスが利けば、タグ取得はO(20・log(P))で、ユーザ名取得はO(20・log(U))だ。20は定数なので消えて、O(log(P))とO(log(U))になる。UはPよりも十分に少ないと仮定すると、全体の支配項はO(log(P))ということになる。つまり、計算量は最も単純な例の時と同じである。
EXPLAIN文で実行計画を調べると、以下の出力が得られる。投稿でヒットしたレコードの各々に対して処理を行うNested Loopがあり、そこでJOINの処理を行っている。結合先のテーブルからデータを取り出すにあたっては全てインデックスが使われ、一部はキャッシュも使われていて、DB本体のシーケンシャルスキャン(Seq Scan)やインデックスのシーケンシャルスキャン(Filter)がひとつもなく、全てがインデックスの条件付き絞り込み(Index Cond)の理想的な処理になっていることがわかる。
Limit (cost=1.17..106.53 rows=20 width=133)
-> Nested Loop Left Join (cost=1.17..159137.24 rows=30210 width=133)
-> Nested Loop Left Join (cost=0.89..14010.38 rows=30210 width=100)
-> Nested Loop (cost=0.58..13250.15 rows=30210 width=92)
-> Index Scan Backward using idx_posts_root_id on posts p (cost=0.29..3512.64 rows=30210 width=83)
-> Memoize (cost=0.30..0.41 rows=1 width=17)
Cache Key: p.owned_by
Cache Mode: logical
-> Index Scan using users_pkey on users u (cost=0.29..0.40 rows=1 width=17)
Index Cond: (id = p.owned_by)
-> Memoize (cost=0.30..0.46 rows=1 width=16)
Cache Key: p.reply_to
Cache Mode: logical
-> Index Scan using posts_pkey on posts parent_post (cost=0.29..0.45 rows=1 width=16)
Index Cond: (id = p.reply_to)
-> Index Scan using users_pkey on users pu (cost=0.29..0.35 rows=1 width=17)
Index Cond: (id = parent_post.owned_by)
SubPlan 1
-> Index Only Scan using post_tags_pkey on post_tags pt2 (cost=0.42..4.45 rows=2 width=7)
Index Cond: (post_id = p.id)listPostsByFollowees
STGYのSNSとしての典型的なビューは、「自分がフォローしているユーザの投稿の一覧」を見ることである。これがログイン直後のデフォルトのビューでもある。このクエリが効率的に処理できるかどうかがSNSの性能を決めると言って良い。
基本戦略としては、表示件数が20件という定数であることを利用して計算量の削減を図る。全フォロイーの中から直近の投稿が新しい20人を選び、その20人の各々の最新の投稿20件を取り出すことで、最大400件のソートしかしないことが保証できる。実際のクエリは以下のものだ。
WITH
all_followees AS (
SELECT followee_id
FROM user_follows
WHERE follower_id = 0x0001000000000013),
active_followees AS (
SELECT DISTINCT ON (p2.owned_by) p2.owned_by, p2.id AS last_id
FROM posts p2
WHERE p2.owned_by IN (SELECT followee_id FROM all_followees)
ORDER BY p2.owned_by, p2.id DESC),
top_followees AS (
SELECT owned_by
FROM active_followees
ORDER BY last_id DESC LIMIT 20),
candidates AS (
SELECT pid.id
FROM top_followees tf
JOIN LATERAL (
SELECT p2.id
FROM posts p2
WHERE p2.owned_by = tf.owned_by
ORDER BY p2.id DESC LIMIT 20) AS pid ON TRUE),
top_posts AS (
SELECT id
FROM candidates
ORDER BY id DESC OFFSET 0 LIMIT 20)
SELECT
p.id, p.snippet, p.owned_by, p.reply_to,
p.allow_likes, p.allow_replies, p.updated_at,
u.nickname AS owner_nickname, pu.nickname AS reply_to_owner_nickname,
ARRAY(SELECT pt2.name FROM post_tags pt2
WHERE pt2.post_id = p.id ORDER BY pt2.name) AS tags
FROM top_posts t
JOIN posts p ON p.id = t.id
JOIN users u ON p.owned_by = u.id
LEFT JOIN posts parent_post ON p.reply_to = parent_post.id
LEFT JOIN users pu ON parent_post.owned_by = pu.id
ORDER BY t.id DESC;クエリが込み入っているので、部分ごとに解説しよう。
- フォローしているユーザのIDの一覧をall_followeesというビューとして作る。
- all_followeesの各々について最新の投稿IDを紐づけたactive_followeesというビューを作る。
- active_followeesの内容を投稿IDでソートして、最も最近に投稿をしたトップ20人のユーザIDの集合であるtop_followeesというビューを作る。
- top_followeesの各ユーザIDにJOIN LATERALして、各ユーザの最新投稿IDを20件ずつ取り出したcandidatesというビューを作る。
- candidatesの最大400件の投稿IDをソートして、最新20件に絞ったtop_postsというビューを作る。
- top_postsの各々のIDに対して、listPostsと同様に、各種属性を肉付けする。
これの計算量を考えよう。全ユーザ数をUと置き、全投稿数をPと置き、フォローしているユーザ数をFと置く。フォローしているユーザの一覧を引くのは、インデックスが利けば、O(log(U))だ。フォローしているユーザの各々の最新投稿を調べるのは、インデックスが利けば、O(F・log(P))だ。F人から最新アクティブユーザ20人を選ぶのはtop-kヒープなので、O(F・log(20)) で、20は定数なので、O(F)だ。最新アクティブユーザ20人の各々の最新投稿20件を取り出すと、400件が取れる。400件から20件を選ぶのもtop-kヒープなので、O(400・log(20))で、400も20も定数なので、O(1)だ。そして20件の各々に肉付けする処理は、全てインデックスが利くなら、O(20・log(P))で、20は定数なので、O(log(P))だ。つまり、UはPよりも少ないと仮定すると、全体の計算量の支配項はO(F・log(P))ということになる。Pは莫大に大きくても大丈夫だし、Fはそこそこ大きくても大丈夫ということになる。
あとは、各処理でちゃんとインデックスが効いているかどうかを確かめれば良い。上述のクエリをEXPLAINにかけてみると、以下の出力が得られる。全てがIndex Condの理想的な実行計画になっていることが確かめられた。
Nested Loop Left Join (cost=77.17..186.79 rows=8 width=141)
-> Nested Loop Left Join (cost=76.88..148.35 rows=8 width=108)
-> Nested Loop (cost=76.59..145.31 rows=8 width=100)
-> Nested Loop (cost=76.31..142.50 rows=8 width=91)
-> Limit (cost=76.02..76.04 rows=8 width=8)
-> Sort (cost=76.02..76.04 rows=8 width=8)
Sort Key: p2_1.id DESC
-> Nested Loop (cost=28.98..75.90 rows=8 width=8)
-> Limit (cost=28.69..28.70 rows=4 width=16)
-> Sort (cost=28.69..28.70 rows=4 width=16)
Sort Key: p2.id DESC
-> Unique (cost=7.56..28.65 rows=4 width=16)
-> Incremental Sort (cost=7.56..28.64 rows=4 width=16)
Sort Key: p2.owned_by, p2.id DESC
Presorted Key: p2.owned_by
-> Nested Loop (cost=0.58..28.46 rows=4 width=16)
-> Index Only Scan using user_follows_pkey on user_follows (cost=0.29..8.32 rows=2 width=8)
Index Cond: (follower_id = '281474976710675'::bigint)
-> Index Only Scan using idx_posts_owned_by_id on posts p2 (cost=0.29..10.05 rows=2 width=16)
Index Cond: (owned_by = user_follows.followee_id)
-> Limit (cost=0.29..11.77 rows=2 width=8)
-> Index Only Scan Backward using idx_posts_owned_by_id on posts p2_1 (cost=0.29..11.77 rows=2 width=8)
Index Cond: (owned_by = p2.owned_by)
-> Index Scan using posts_pkey on posts p (cost=0.29..8.31 rows=1 width=83)
Index Cond: (id = p2_1.id)
-> Index Scan using users_pkey on users u (cost=0.29..0.35 rows=1 width=17)
Index Cond: (id = p.owned_by)
-> Index Scan using posts_pkey on posts parent_post (cost=0.29..0.38 rows=1 width=16)
Index Cond: (id = p.reply_to)
-> Index Scan using users_pkey on users pu (cost=0.29..0.35 rows=1 width=17)
Index Cond: (id = parent_post.owned_by)
SubPlan 1
-> Index Only Scan using post_tags_pkey on post_tags pt2 (cost=0.42..4.45 rows=2 width=7)
Index Cond: (post_id = p.id)最新アクティブユーザの各々から表示件数である20件分取得するのは、確実に時系列に最新の投稿を表示するためである。一人のユーザが最新投稿の全てを占める可能性があるからだ。しかし、タイムライン表示で同じユーザの投稿ばかりが占めるというのは嬉しいものではない。そこで、実運用では、ユーザ毎の取得件数をパラメータで指定できるようにして、そのデフォルトは3にする。ソートするのは60件で済むため、より高速化することになる。投稿を取得するコストが軽くなると、最新アクティブユーザを調べるコストの比重が高くなることになる。さらに高速化するには、ユーザ毎の最新投稿時刻をテーブルに分割して持っておくとよい。これも典型的な非正規化だが、O(F・log(P))である支配項がO(F・log(U))になるわけで、確実に効果がある。今回はそこまではやっていないが、タイムラインが重くなったらまず試すべき最適化だ。
ユーザ毎の取得件数を減らすほど、より多くのユーザの最新投稿が表示でき、性能上も利点がある。多数投稿するユーザに関しては、そのユーザの詳細画面から最新投稿一覧を見てもらえば良い。ならば、なぜ1件ではなく3件にするのか。それは、各ユーザの既読の投稿と未読の投稿が1件以上ずつ目に入ると効率が良く、1件足すことでどちらかが0になることを防ぎたいからだ。未読の投稿だけを見ると、そのユーザがもっと未読の投稿をしているかもしれないので、ユーザ詳細画面に遷移して確認したくなる。しかし、ページをめくっているうちにユーザの既読の投稿も目にしている場合、未読の投稿はもうないことがわかる。既読の投稿だけを見るのは、単なる徒労である。投稿のためのアクセスの頻度よりも、閲覧のためのアクセスの頻度の方が高いのが一般的で、多くのユーザが似たような頻度でアクセスすると仮定すると、3件くらいが最もバランスが良さそうだ。とはいえ、最善の設定はユーザ行動分析を経て導くべきだろう。
listPostsLikedByUser
自分がイイネした投稿の一覧を得るには、以下のクエリが使われる。
SELECT
p.id, p.snippet, p.owned_by, p.reply_to,
p.allow_likes, p.allow_replies, p.updated_at,
u.nickname AS owner_nickname, pu.nickname AS reply_to_owner_nickname,
ARRAY(SELECT pt.name FROM post_tags pt
WHERE pt.post_id = p.id ORDER BY pt.name) AS tags
FROM post_likes pl
JOIN posts p ON pl.post_id = p.id
JOIN users u ON p.owned_by = u.id
LEFT JOIN posts pp ON p.reply_to = pp.id
LEFT JOIN users pu ON pp.owned_by = pu.id
WHERE pl.liked_by = 0x0001000000000013
ORDER BY pl.created_at DESC OFFSET 0 LIMIT 20;liked_byでの絞り込みにインデックスが利きさえすれば、計算量はlistPostsと同じくO(log(P))で済むはずだ。あとは実行計画見れば、それが確認できる。
Limit (cost=1.44..106.72 rows=6 width=141)
-> Nested Loop Left Join (cost=1.44..106.72 rows=6 width=141)
-> Nested Loop Left Join (cost=1.15..77.90 rows=6 width=108)
-> Nested Loop (cost=0.86..75.61 rows=6 width=100)
-> Nested Loop (cost=0.58..73.50 rows=6 width=91)
-> Index Scan Backward using idx_post_likes_liked_by_created_at on post_likes pl (cost=0.29..23.66 rows=6 width=16)
Index Cond: (liked_by = '281474976710675'::bigint)
-> Index Scan using posts_pkey on posts p (cost=0.29..8.31 rows=1 width=83)
Index Cond: (id = pl.post_id)
-> Index Scan using users_pkey on users u (cost=0.29..0.35 rows=1 width=17)
Index Cond: (id = p.owned_by)
-> Index Scan using posts_pkey on posts pp (cost=0.29..0.38 rows=1 width=16)
Index Cond: (id = p.reply_to)
-> Index Scan using users_pkey on users pu (cost=0.29..0.35 rows=1 width=17)
Index Cond: (id = pp.owned_by)
SubPlan 1
-> Index Only Scan using post_tags_pkey on post_tags pt (cost=0.42..4.45 rows=2 width=7)
Index Cond: (post_id = p.id)listUsers
usersテーブルを操作するusersServiceという実装にも各種メソッドがあって、それぞれクエリを発行している。どれも軽い処理だが、ユーザの一覧を出すlistUsersだけは、注意を要する。例えば、ユーザのニックネームの前方一致条件で絞り込みを行いつつ、フォロイーもしくはフォロワーを優先して表示するという特殊機能がある。そのクエリは以下のものだ。
SELECT u.id, u.email, u.nickname, u.is_admin, u.snippet, u.avatar, u.ai_model, u.updated_at FROM users u LEFT JOIN user_follows f1 ON f1.follower_id = 0x0001000000000013 AND f1.followee_id = u.id LEFT JOIN user_follows f2 ON f2.follower_id = u.id AND f2.followee_id = 0x0001000000000013 WHERE LOWER(u.nickname) LIKE 'user0002%' ORDER BY (u.id = 0x0001000000000013) DESC, (f1.follower_id IS NOT NULL) DESC, (f2.follower_id IS NOT NULL) DESC, u.id ASC OFFSET 0 LIMIT 20;
LIKE演算子による前方一致は、インデックスが利くので、絞り込みを効率的に行うことができる。絞り込んだ上で最後にソートで順位付けするため、ヒット件数が少なければ高速に動く。EXPLAIN文の結果は以下である。
Limit (cost=25.12..25.13 rows=3 width=309)
-> Sort (cost=25.12..25.13 rows=3 width=309)
Sort Key: ((u.id = '281474976710675'::bigint)) DESC, ((f1.follower_id IS NOT NULL)) DESC, ((f2.follower_id IS NOT NULL)) DESC, u.id
-> Nested Loop Left Join (cost=0.87..25.10 rows=3 width=309)
Join Filter: (f2.follower_id = u.id)
-> Nested Loop Left Join (cost=0.58..16.73 rows=3 width=314)
Join Filter: (f1.followee_id = u.id)
-> Index Scan using idx_users_nickname_id on users u (cost=0.29..8.31 rows=3 width=306)
Index Cond: ((lower((nickname)::text) ~>=~ 'user0002'::text) AND (lower((nickname)::text) ~<~ 'user0003'::text))
Filter: (lower((nickname)::text) ~~ 'user0002%'::text)
-> Materialize (cost=0.29..8.33 rows=2 width=16)
-> Index Only Scan using user_follows_pkey on user_follows f1 (cost=0.29..8.32 rows=2 width=16)
Index Cond: (follower_id = '281474976710675'::bigint)
-> Materialize (cost=0.29..8.31 rows=1 width=8)
-> Index Scan using idx_user_follows_followee_created_at on user_follows f2 (cost=0.29..8.31 rows=1 width=8)
Index Cond: (followee_id = '281474976710675'::bigint)さて、多くの処理がインデックスを使って行われているので、このクエリは一見速そうだ。実際、絞り込みの文字列が十分に長くてヒット件数が少ない場合には、最下層の文字列インデックスが効率的に働いて、少ない数のレコードを一瞬で返し、ハッシュマップを使って各々のレコードに効率的にスコアリングを施した上で、一瞬で処理を返してくれるだろう。問題は、絞り込みの文字列が短く、ヒット数が多い場合である。その場合、ヒットしたレコードの全てにスコアリングをしてからソートすることになるため、遅くなる。全ユーザ数をUとした場合、絞り込み文字列が1文字なら、Uの何割かがヒットしてしまうので、空間計算量はO(U)となる。それをtop-kヒープでソートする時間計算量は、kが20と小さいので、O(U)である。
なお、LIKE演算子による前方一致検索を効率的に動かすには、ちょっとしたコツがある。DBを作る際に、POSTGRES_INITDB_ARGS: "--encoding=UTF8 --locale=C --lc-collate=C --lc-ctype=en_US.UTF-8" などと指定して、コレーションを無効化することだ。Postgresのデフォルトでは文字列の比較を厳密なバイト比較ではなく、複数の文字を同一視するコレーションをした上で比較する。コレーションがあると、デフォルトのインデックスがLIKE演算子で使えない。その他の場面でも、コレーションのせいで効率が悪化することがありうるので、デフォルトのコレーションは切っておいた方が無難だ。後でコレーションが必要になったら、特定の列だけに指定すれば良い。なお、ロケールはen_US.UTF-8などにしておくと、LOWER/UPPERなどの関数は非ASCIIのギリシャ文字やキリル文字にも対応した挙動になる。ja_JP.UTF-8にしても挙動は同じだ。CにしてしまうとASCIIの英字しか処理してくれなくなる。
コレーションを無効化したとしても、大文字と小文字の違いを無視するILIKE演算子には、デフォルトのインデックスは使えない。よって、nicknameのインデックスは LOWER(nickname) text_pattern_ops として小文字に正規化したものにしている。小文字に正規化したインデックスを十全に働かせるには、上述のクエリのように、クエリ内の条件も小文字に正規化する必要がある。そうでない場合、インデックスが使われない。
# EXPLAIN SELECT id FROM users WHERE LOWER(nickname) LIKE 'user0002%' ORDER BY ID LIMIT 3;
Limit (cost=8.34..8.34 rows=3 width=8)
-> Sort (cost=8.34..8.34 rows=3 width=8)
Sort Key: id
-> Index Scan using idx_users_nickname_id on users (cost=0.29..8.31 rows=3 width=8)
Index Cond: ((lower((nickname)::text) ~>=~ 'user0002'::text) AND (lower((nickname)::text) ~<~ 'user0003'::text))
Filter: (lower((nickname)::text) ~~ 'user0002%'::text)
# EXPLAIN SELECT id FROM users WHERE nickname LIKE 'user0002%' ORDER BY ID LIMIT 3;
Limit (cost=984.21..984.22 rows=3 width=8)
-> Sort (cost=984.21..984.22 rows=3 width=8)
Sort Key: id
-> Seq Scan on users (cost=0.00..984.19 rows=3 width=8)
Filter: ((nickname)::text ~~ 'user0002%'::text)listFriendsByNicknamePrefix
さて、上述のlistUsersメソッドは、それに与えられた外部仕様を満たすためには最善の実装ではあるが、SNSの実運用に供するには効率が悪すぎる。そこで、仕様を単純化したlistFriendsByNicknamePrefixという専用メソッドを設けた。ユーザリストはIDの昇順か降順で返すという原則を崩して、自分、フォロイー、その他の分類順で、各分類の中ではニックネームの辞書順にするという特殊仕様だ。あまりこういう専用メソッドを作りたくはないのだが、こればっかりはやらないと仕方がない。基本戦略としては、自分、フォロイー、その他大勢、を別々に処理して絞り込んでから、最後にUNION ALL結合する。具体的なクエリは以下のものだ。
WITH
self AS (
SELECT
0 AS prio,
u.id, lower(u.nickname) AS nkey
FROM users u
WHERE u.id = 0x0001000000000013 AND lower(u.nickname) LIKE 'user0002%' ),
followees AS (
SELECT
1 AS prio, u.id, lower(u.nickname) AS nkey
FROM user_follows f
JOIN users u ON u.id = f.followee_id
WHERE f.follower_id = 0x0001000000000013 AND lower(u.nickname) LIKE 'user0002%'
ORDER BY lower(u.nickname), u.id LIMIT 20 ),
others AS (
SELECT
3 AS prio, u.id, lower(u.nickname) AS nkey
FROM users u
WHERE lower(u.nickname) LIKE 'user0002%'
ORDER BY lower(u.nickname), u.id LIMIT 20 ),
candidates AS (
SELECT * FROM self
UNION ALL
SELECT * FROM followees
UNION ALL
SELECT * FROM others ),
dedup AS (
SELECT DISTINCT ON (id)
id, prio, nkey
FROM candidates
ORDER BY id, prio ),
page AS (
SELECT
id, prio, nkey
FROM dedup
ORDER BY prio, nkey, id OFFSET 0 LIMIT 20 )
SELECT
u.id, u.email, u.nickname, u.is_admin, u.snippet, u.avatar,
u.ai_model, u.updated_at
FROM page p
JOIN users u ON u.id = p.id
ORDER BY p.prio, p.nkey, u.id;selfとfolloweesとothersの3つの枝のそれぞれで最大20件のレコードだけを取り出していて、それぞれが20件だけのスキャンで早期終了することを企図している。取り出すレコードも優先度とIDとニックネームだけの最低限に絞っている。そして、dedup処理では、id, prio, nkeyでソートしてから重複IDを除いていて、prioの最小値が採択されている。最後に最終順序でソートした20件だけに他の属性を肉付けして返している。
これの計算量を考えよう。全ユーザ数をUと置き、フォロイー数をFと置く。自分を調べるのは、O(log(U))だ。フォロイーの一覧を引くのは、O(log(U)+F)だ。検索文字列が短い場合、ほとんど絞り込みが働かないので、フォロイー全員のニックネームを調べることになる。よって、その計算量はO(F・log(U))だ。フォロイーのヒット全てを並び替える計算量はO(F・log(F))だ。全員を調べる枝では、検索文字列が短い場合でも、確実に早期終了するので、計算量はO(log(U))だ。つまり、FはUより十分に小さいと仮定すると、支配項はO(F・log(U))ということになる。EXPLAIN文の結果は以下である。全ての枝(Subquery)でIndex Condが働いていて、早期終了するので、効率は最善だ。フォロイーの枝でフォロイー毎にレコードを調べているのもわかる。
Nested Loop (cost=33.92..75.22 rows=5 width=342)
-> Limit (cost=33.63..33.64 rows=5 width=44)
-> Sort (cost=33.63..33.64 rows=5 width=44)
Sort Key: "*SELECT* 1".prio, "*SELECT* 1".nkey, "*SELECT* 1".id
-> Unique (cost=33.55..33.57 rows=5 width=44)
-> Sort (cost=33.55..33.56 rows=5 width=44)
Sort Key: "*SELECT* 1".id, "*SELECT* 1".prio
-> Append (cost=0.29..33.49 rows=5 width=44)
-> Subquery Scan on "*SELECT* 1" (cost=0.29..8.32 rows=1 width=44)
-> Index Scan using users_pkey on users u_1 (cost=0.29..8.31 rows=1 width=44)
Index Cond: (id = '281474976710675'::bigint)
Filter: (lower((nickname)::text) ~~ 'user0002%'::text)
-> Subquery Scan on followees (cost=16.75..16.76 rows=1 width=44)
-> Limit (cost=16.75..16.75 rows=1 width=44)
-> Sort (cost=16.75..16.75 rows=1 width=44)
Sort Key: (lower((u_2.nickname)::text)), u_2.id
-> Nested Loop (cost=0.58..16.74 rows=1 width=44)
Join Filter: (f.followee_id = u_2.id)
-> Index Scan using idx_users_nickname_id on users u_2 (cost=0.29..8.31 rows=3 width=17)
Index Cond: ((lower((nickname)::text) ~>=~ 'user0002'::text) AND (lower((nickname)::text) ~<~ 'user0003'::text))
Filter: (lower((nickname)::text) ~~ 'user0002%'::text)
-> Materialize (cost=0.29..8.33 rows=2 width=8)
-> Index Only Scan using user_follows_pkey on user_follows f (cost=0.29..8.32 rows=2 width=8)
Index Cond: (follower_id = '281474976710675'::bigint)
-> Subquery Scan on others (cost=8.34..8.38 rows=3 width=44)
-> Limit (cost=8.34..8.35 rows=3 width=44)
-> Sort (cost=8.34..8.35 rows=3 width=44)
Sort Key: (lower((u_3.nickname)::text)), u_3.id
-> Index Scan using idx_users_nickname_id on users u_3 (cost=0.29..8.32 rows=3 width=44)
Index Cond: ((lower((nickname)::text) ~>=~ 'user0002'::text) AND (lower((nickname)::text) ~<~ 'user0003'::text))
Filter: (lower((nickname)::text) ~~ 'user0002%'::text)
-> Index Scan using users_pkey on users u (cost=0.29..8.30 rows=1 width=306)
Index Cond: (id = "*SELECT* 1".id)fetchBatch
通知を作成するワーカーがイベントログを読み出す際には、以下のようなクエリが実行される。
SELECT event_id, payload FROM event_logs WHERE partition_id = 2 AND event_id > 1843013374800035840 ORDER BY partition_id, event_id LIMIT 100;
主キーがpartition_idとevent_idの複合キーなので、そのインデックスを使えば効率的な実行計画になるはずだ。イベントログの件数をEとすると、計算量はO(log(E))で済む。非同期処理なので読み出すレコードの数は何件でもよいのだが、何らか理由でワーカーの起動が遅延した際に未処理のイベントを適度なペースで処理するには、100件くらいが丁度よいだろう。
このクエリには落とし穴がある。event_id単体での検索性を確保するためにevent_idにユニーク制約をつけると、そのインデックスを使ってevent_idの対象範囲をスキャンしながら該当のpartition_idのものを拾ってしまうのだ。そこで、そのユニーク制約を除外したところ、以下のような効率的な実行計画になることが確認できた。更新イベントが発生する度にこのクエリは実行されるので、この処理が非効率だと洒落にならない負荷になってしまう。理論的に最善であろうインデックスを張って安心しては不十分で、きちんと実行計画を確認しないと後で地獄を見る。
Limit (cost=0.42..28.02 rows=100 width=95)
-> Index Scan using event_logs_pkey on event_logs (cost=0.42..8330.90 rows=30179 width=95)
Index Cond: ((partition_id = 2) AND (event_id > '1843013374800035840'::bigint))listFeed
作成された通知を読み出す際には、以下のようなクエリが実行される。
SELECT slot, term, is_read, payload, updated_at, created_at FROM notifications WHERE user_id = 0x0001000000000013 AND is_read = FALSE ORDER BY updated_at DESC LIMIT 20;
新規通知の有無は定期的に調べられるので、このクエリの効率も重要だ。user_id、is_read、updated_atの複合インデックスを設けているので、そのインデックスが使われるはずだ。通知件数をNとすると、計算量はO(log(N))になる。実行計画を見ても、そのことが確認できる。なお、未読リストと既読リストはis_readの条件値を変えて2回のクエリに分けて取得し、結合結果をIDでソートして最新20件を提示する。この方法だと、ページ送り機能がないUIでも、ひとつひとつ既読にしていくことで、全ての通知を閲覧できる。
Limit (cost=0.29..15.46 rows=5 width=136)
-> Index Scan Backward using idx_notifications_user_read_ts on notifications (cost=0.29..15.46 rows=5 width=136)
Index Cond: ((user_id = '281474976710675'::bigint) AND (is_read = false))新着通知を調べる際に、毎回同じデータを返すのは無駄だ。よって、クライアントが最後に取得した通知の最新のupdated_atをパラメータとして渡すAPIになっていて、それより新しい未読レコードがなければ304を返すという仕様になっている。
SELECT 1 FROM notifications WHERE user_id = 0x0001000000000013 AND is_read = FALSE AND updated_at > '2025-09-12 04:17:15.536+00' LIMIT 1;
この計算量も当然O(log(N))である。実行計画を見てもインデックスが適切に効いていることがわかる。ここで重要なのは、is_read = FALSEを指定して、未読だけを調べていることだ。インデックスの構造に合わせた条件を全て指定することでインデックスがIndex Only Scanにしている。最新の通知は常に未読なので、未読だけ調べれば十分だ。
Limit (cost=0.29..1.91 rows=1 width=4)
-> Index Only Scan using idx_notifications_user_read_ts on notifications (cost=0.29..8.40 rows=5 width=4)
Index Cond: ((user_id = '281474976710675'::bigint) AND (is_read = false) AND (updated_at > '2025-09-12 04:17:15.536+00'::timestamp with time zone))総評
ここまで見てきたように、記事IDやユーザIDのリストを取得するための検索操作は全てインデックス上で行えるように、スキーマとクエリを設計している。各々のインデックスは小さいので、大部分がメモリ上にキャッシュされて、高速にランダムアクセスできる。よって、STGYの主要クエリは、全てスケールするものになっていると言える。
全体の最新投稿を一覧で使うlistPostsの計算量はO(log(P))だ。自分がフォローしているユーザの最新投稿を一覧で使うlistPostsByFolloweesの計算量はO(F・log(P))で済んでいる。イイネした投稿の一覧で使うlistPostsLikedByUserの計算量はO(log(P))だ。その他、全ての投稿一覧はO(log(P))以下の計算量に留めている。ユーザ一覧に関しても同様で、全文検索以外で最も重いlistFriendsByNicknamePrefixの計算量もO(F・log(U))に留めている。
最も重いlistPostsByFolloweesとlistFriendsByNicknamePrefixの計算量はフォロイー数Fに比例する。したがって、フォロイー数を定数項にするために、上限値を決める必要がある。現実的には100人以上フォローしても使い勝手が悪くなるだけなので、200人くらいを上限値にすれば問題ないだろう。Fが定数であれば、計算量はO(log(P))とO(log(U))と表せるわけで、誰がどう見ても健全なシステムになる。
UXの要求仕様でフォロイー数の制限ができない場合、毎回のクエリでフォローしている全員を対象にするのではなく、何らかの簡便法を用いるのが現実的だ。例えば、「重要フォロイー」のサブセットを定期的に抽出してキャッシュに持たせておいて、それを使いつつも、あたかも全員を対象としているかのような振りをするのだ。TwitterもFacebookも当然そうしている。
投稿記事の本文やユーザ自己紹介の本文などのでかいデータを取得する操作も、スケーラビリティの制限要因になる。主キーに紐づいたテーブル本体のレコードを読み出すという操作は、レコード数Nに対してO(log(N))の計算量に過ぎない。しかし、データの規模が大きいと遅くなる。メモリ上のキャッシュに乗り切らないので、毎回のアクセスでストレージにアクセスするからだ。HDDであればシークタイムも加算される。読み出しのデータが大きいと、ストレージとメモリの間のデータ転送量が増えることでも遅くなる。postsとusersテーブルに本文を入れずにスニペットだけを入れるのは、この問題に対する緩和策だ。計算量を対数オーダーにするのは大前提だが、計算量に現れない最適化も地味に性能に効いてくる。
* 限界点
個々のDBサーバが、いつどのように限界を迎えるのかについて考えておくべきだ。言い換えると、要求スループットに実際のスループットが耐えられなくなる瞬間は、いつ、どのように訪れるかだ。例えば最大100QPSのアクセスがあるなら、クエリ毎のレイテンシは0.01秒未満である必要がある。実際には並列処理能力があるのでそれより少し遅くても大丈夫だが、数倍遅いのはもう駄目だ。
リスト系クエリの処理が、インデックスのみを参照して返却対象のIDを絞り込むフェーズと、主テーブルを参照して個々のIDのレコードの属性を肉付けするフェーズから成ることは既に述べた。クエリの性能が目に見えて落ち始めるのは、インデックスがPostgreSQLのページキャッシュ(shared_buffers)に乗らなくなる瞬間である。ところで、PostgreSQLではページキャッシュは実メモリの25%程度にするのがベストプラクティスとされる。自プロセスの他プロセスのために実メモリを残しておく必要があり、またOSのページキャッシュのためにも実メモリを残しておく必要がある。PostgreSQLはOracleと違ってページキャッシュにダイレクトI/O(O_DIRECT)を使わないので、DBのページキャッシュとOSのページキャッシュの2層構造になっている。
ここで述べる試算はフェルミ推定級の概算であり、設定やデータの特性やアクセスパターンによって実際の数値は全く異なることに注意されたい。仮にメモリ16GBのマシンで運用している場合、DBのページキャッシュの容量は4GBだ。1ページは8KBなので、524288ページが使える。そのうち半分の262144ページをインデックスに使うとする。Bツリーインデックスの各エントリ(タプル)は、典型的には、以下の要素から成る。つまり合計28バイトだ。なぜUUIDでなくSnowflake IDを使うべきかを実感するところだ。
- 検索キー(今回の典型ではSnowflake ID)(8B)
- 順序キー(今回の典型ではSnowflake ID)(8B)
- アイテムポインタ(6B)
- インフォ(長さ・フラグ)(2B)
- ラインポインタ(オフセット・タプル長・フラグ)(4B)
単純計算すると1ページに292エントリが入ることになる。しかし、実際にはページヘッダやBツリーのヘッダが入り、フィルファクタで90%までしかデータを埋めないという制約があり、さらにページ分割によるフラグメンテーションも起こるので、200エントリくらいで見ておくと安全だ。よって、システム全体で52428800エントリがキャッシュに乗る。投稿関係でそのうち80%を使うとすると、41943040エントリだ。postsテーブルには、主キーに自動的に張られるインデックスを含めて、5つのインデックスがつけられている。最終的に、約840万(41943040 / 5 = 8388608)投稿分のインデックスがキャッシュに乗るという試算になる。それよりも小さい規模だとほぼすべてのクエリはオンメモリで処理されるが、それを超えると、確率的にディスクI/Oが発生するようになる。とはいえ、インデックスには参照局所性があり、新しいデータにアクセスが偏り、OSのページキャッシュもあるので、840万件を過ぎた時にいきなりガクンと遅くなるわけではない。ジワジワと、しかし確実に、遅くなり始める。対数オーダーではあるが、インデックス内のランダムアクセス回数の増加も係数として効いてくる。
主テーブルのデータも840万とは別の閾値でキャッシュに載らなくなってくるが、その閾値はより少ない件数だろう。主テーブルの方がデータが大きいのだから、主テーブルがページキャッシュを食い尽くすという懸念もあるが、実際にはアクセス頻度が高いインデックスデータの方がページキャッシュに残りやすい。主テーブルのアクセスは絞り込みが終わってから定数回しか行われないようにクエリ設計するのはキャッシュ効率の点でも重要だ。もしも主テーブルをシーケンシャルスキャンすると、ページキャッシュが荒らされてしまう。また、SNSの場合、新しいレコードに参照が偏るので、表示するレコードだけを読み込むようにすると、参照局所性が高く維持できる。投稿の主テーブル以外にもタグのインデックスが参照されるが、それも同じアクセスパターンになる。
実際のテーブルやインデックスが占有しているデータサイズは、以下のクエリで分かる。実運用を始めたら、定期的にその結果を見て限界予測をすべきだ。人気サービスのSREに抜擢されたなら、毎日この時限爆弾を眺める栄誉が与えられる。
CREATE EXTENSION IF NOT EXISTS pageinspect;
SELECT
n.nspname AS schema,
c.relname AS name,
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 't' THEN 'toast'
WHEN 'i' THEN 'index'
WHEN 'm' THEN 'mview'
ELSE c.relkind::text
END AS type,
pg_size_pretty(pg_relation_size(c.oid)) AS size_pretty,
pg_relation_size(c.oid)/8192 AS pages_8k
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE n.nspname NOT IN ('pg_catalog','information_schema')
AND c.relkind IN ('r','t','i','m')
ORDER BY pages_8k DESC;投稿20万件をDBに記録した際の実際のインデックスのサイズとページ数を以下に示す。半分は返信、半分は新規投稿とする。
| 機能 | 名前 | サイズ | ページ数 |
|---|---|---|---|
| posts主キー | posts_pkey | 6332416 | 773 |
| posts著者別インデックス | idx_posts_owned_by_id | 9494528 | 1159 |
| posts返信別インデックス | idx_posts_reply_to_id | 8888320 | 1085 |
| posts非返信インデックス | idx_posts_root_id | 2285568 | 279 |
| posts非返信著者別インデックス | idx_posts_root_owned_by_id | 3186688 | 389 |
インデックスのサイズの合計は30187520バイトであり、投稿あたり150バイトだと実測された。1.7GB(4GBの半分の80%)に乗る件数は11145万件ということになる。840件の試算よりも多くなったのは、返信別インデックスと非返信別が排他的であることと、バッチで整然と登録したのでフラグメンテーションが起きにくかったことと、そもそも試算の際のページ内エントリを厳しめに見積もっていたことに起因すると考えられる。いずれにせよ、最悪840万件、最善1145万件くらいの幅で飽和点を捉えておくと良いだろう。
ページキャッシュに乗らなくなったデータの読み書きは、ストレージのI/O性能に律速される。HDDだと速くて200 IOPSで、SSDだと遅くて500000 IOPSだ。HDDだとページキャッシュに乗らなくなった時点で即座に死亡フラグが立つのだが、SSDだとその後も耐え続ける。840万投稿程度の規模であれば100QPSとかは余裕で出るだろう。ストレージの性能は製品によって全然違うので、最終的にどの程度の規模でどの程度のスループットが出るのかは、実運用環境で実験してみないとわからない。AWSで運用する場合、RDSでもAuroraでも、設定によって性能が大きく変わる。ページキャッシュの飽和点は計算で導けるが、実際のスケーラビリティの限界点はベンチマークテストを経てから判断すべきだ。
余談
スニペットをDBに保存するということは、「どう表示するか」というフロントエンド側のプレゼンテーションの知識をバックエンド側で持つことを意味するため、責任分割の観点では気持ち悪い。本文に関数従属しているスニペットを持つのは第3正規形の違反でもある。スニペットの形式や文字数制限を変えた際にDBのレコードを入れ直さなきゃならないのも嫌だ。しかし、その気持ち悪さを飲んでもやらねばならない。
投稿記事やユーザ自己紹介の本文を分離するという手法は、いわゆる垂直分割の一種である。属性データの特性に合わせて管理方法を分割する手法とも言える。本文だけDBサーバを分けてもいいし、列指向DBに入れてもいいし、S3に入れてクライアントに直接取得させたっていい。古い記事の本文は圧縮した上でアーカイブ用のストレージに入れてもいい。post_likesやuser_followsといったテーブルを別サーバで管理するのも良いだろう。
以上のことを鑑みると、リソースのリストを取得する処理は、常に二段構えで考えるべきだ。条件に該当するIDのリストを生成する段と、そのIDに紐づけて属性を収集する段だ。RDB1台運用だとその2段が一発のクエリでできるが、それでもサブクエリを使って敢えて2段に分けて書くのも良い考えだ。以下の二つのクエリは等価で、後者の方が若干遅いかもしれないが、いずれ垂直分割する際は、後者の書き方をしておく方がバグりにくい。
SELECT id, nickname, snippet FROM USERS WHERE id > 0x0001000000000002 ORDER BY id LIMIT 10; WITH cand_ids AS ( SELECT id FROM users WHERE id > 0x0001000000000002 ORDER BY id LIMIT 10 ) SELECT u.id, u.nickname, u.snippet FROM users AS u JOIN cand_ids AS c ON u.id = c.id ORDER BY c.id;
なお、PostgreSQLでは、TOAST(The Oversized-Attribute Storage Technique)という機構があり、2KBを超える大きい列データを暗黙的に圧縮したり別領域に移動したりしてくれる。よって、明示的に分割しなくても、ある程度の最適化は勝手になされる。しかし、それでもなお、大きさや参照頻度が異なるデータは明示的に分割した方が良い。今回の例では、スニペットさえあればリスト取得時には本文を一切参照する必要がない。たとえSELECT文で属性を指定しなくても、同じテーブルにある限り、データは読み込まれてしまう。よって、本文は短くても長くても別テーブルに逃がした方が、主テーブルのページ読み出し量が少なくて済む。
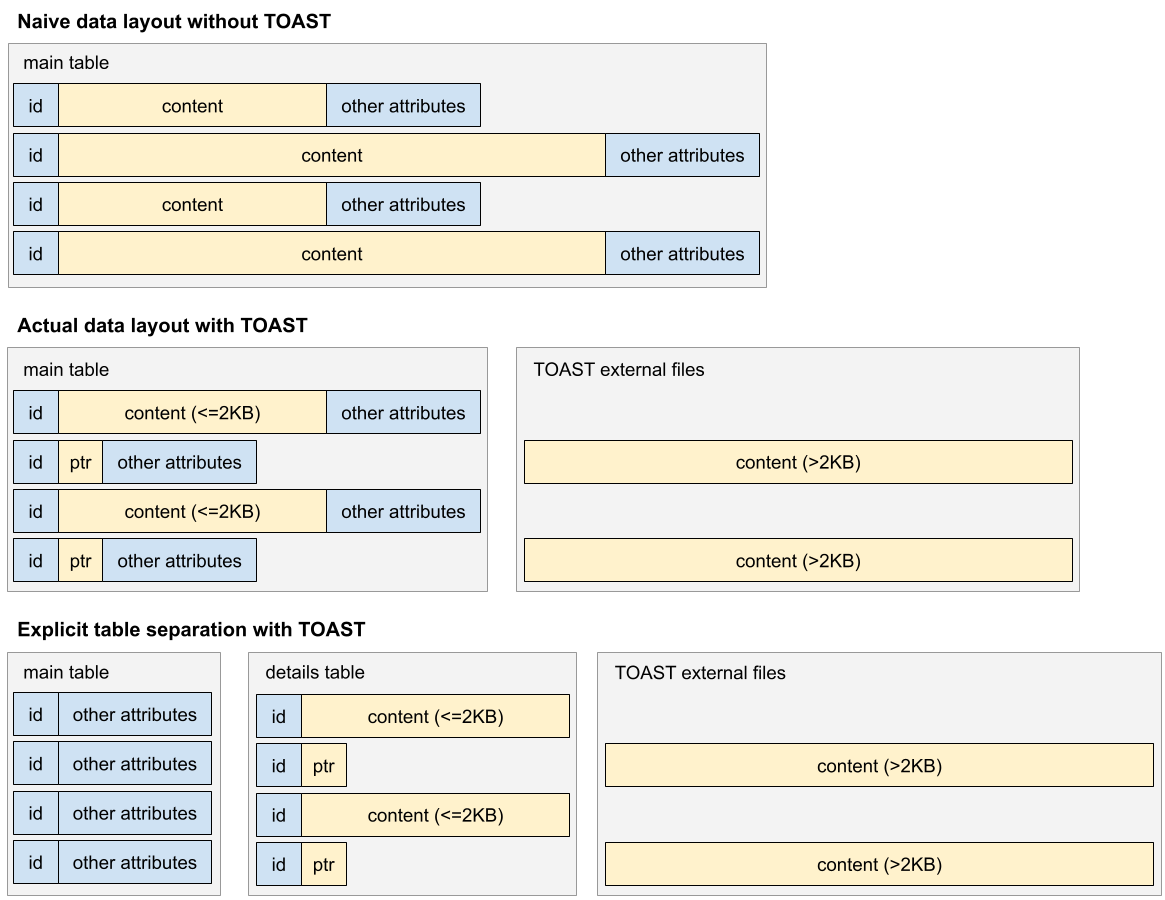
指定した列の短いデータも強制的にTOASTしてくれれば、わざわざテーブル分割しなくても済むのにと思ったが、そのような指定はできない。また、テーブル分割した先では、TOASTしなくてもよいとも思ったが、そのような指定もできない。TOASTの本来の目的は参照局所性の向上ではなく、主テーブルの各レコードのサイズをページサイズ(8KB)以下に抑えることだからだ。なお、TOASTは圧縮もしてくれるが、そのデフォルトの圧縮方式はpglz(LZ77)で、遅い割には圧縮率があまり良くない。なので、今回はDB全体の圧縮設定をLZ4に変更している。LZ4は無圧縮に近い速度で動く割には、自然言語の文字列を半分くらいに圧縮する能力があるので、LZ4に変更する利点は大きい。
参照系のクエリが重い場合、マスター・スレーブのレプリケーションを導入すると簡単に負荷分散できる。DBサーバを2台立てて、更新系クエリはマスターサーバにだけ投げるようにする。その更新内容はスレーブサーバに自動的に伝搬する。参照系クエリはマスターとスレーブの双方に分散して投げると、参照系クエリの負荷はサーバあたりで半分になる。スレーブの数を増やせば参照系の負荷はもっと下げられる。マスターが死んだ時にスレーブをマスターに昇格させることで、可用性の向上にもなる。ただし、更新系クエリの負荷はこの方法では下げられない。また、マスターからスレーブに更新が伝搬するまでにタイムラグがあるので、スレーブからの結果をそのまま表示すると直前の更新操作が反映されない可能性がある。よって、更新操作直後の参照系クエリはマスターにだけ投げるとか、更新内容をキャッシュサーバに入れておいてUI上で注入するとか言った工夫が必要になる。
垂直分割やレプリケーションをしても処理しきれなくなってきたら、いよいよ水平分割をすることになる。ユーザIDを使ってパーティショニングを行うのが率直な方法だろう。ハッシュ値などで機械的に割り振っても良いが、各ユーザがどのパーティションに居るのかを管理するuser_partitionsテーブルを作るか、それに相当するKVSを運用するのが率直だ。usersテーブルを引く時はユーザIDでパーティションを特定してからそのDBサーバにアクセスし、postsテーブルを引く時は著者のユーザIDでパーティションを特定してからそのDBサーバにアクセスする。フォロー関係は、フォロー元のユーザとフォロー先のユーザのDBに二重化して持たせれば良い。垂直分割を経ているならば、もはやJOINするクエリは少なくなっていて、IDのリストを取り出してから別のDBにアクセスする作法は確立しているはずだ。あとはそのアクセス先を個々のIDに紐づいたパーティションにするだけだ。ユーザに紐づいた一連のデータをパーティション間で移動するユーティリティさえ書いておけば、運用はそんなに難しくない。
規模が大きくなると、投稿一覧の「All」のビューがほとんど意味をなさなくなってくる。見知らぬ人の投稿を全て見る奴は居ない。となると、「Pickup」とか「Topics」とかいう位置づけのビューを代わりに置くことになるだろう。最近の投稿だけを集めた小さいデータベースを作っておいて、質が高いものや個々のユーザの興味に近そうなものをバッチ処理で計算して、それを提示するのだ。
規模が大きくなると、「セレブユーザ」の存在が運用上の問題になってくる。数万人からフォローされるユーザが出てくるかもしれない。単一の投稿がものすごい勢いでイイネされたり返信されたりするかもしれない。参照系を最適化するだけでは、更新系が逼迫する問題には対処できない。その場合、セレブユーザ専用のデータ管理機構を整備すべきだろう。投稿の内容はキャッシュサーバから配信し、フォローやイイネや返信はキューに入れて非同期に処理する。通知は意味をなさないので処理を省略する。セレブユーザではなくても、突発的なバズりや炎上はあり得る。それに備えて、負荷が一定を超えたら、全体または特定ユーザを対象とする更新操作を非同期処理に切り替える機構を入れてもよいだろう。時間分散という考え方だ。非同期処理にすると更新結果がすぐに画面に反映されないという問題が起こるが、そこはキャッシュで頑張る。つまり、ユーザ毎の更新内容をキャッシュしておいて、あたかもその更新が既にDBに反映されているかのように、表示に細工をするのだ。
その他にも、キャッシュサーバでできることはたくさんある。例えば、listPostsByFolloweesの中で作っているアクティブユーザリストをキャッシュすると、それだけでDBへの負荷が激減する。各アクティブユーザの最新投稿20件の内容もキャッシュしておけば、多くの場合で、DBに全くアクセスしなくても、タイムライン表示が完結する。DB設計の話から逸脱するのでここでは詳述しないが、キャッシュ機構の設計も重要だ。ただし、キャッシュはいつだって消えるので、キャッシュがなくても満足に動くDB設計をするのが大前提だ。
ここまでいろいろ述べたが、STGYの現状の目標は、スケーラビリティを追求することではない。SNSの基本機能を率直に実装した、シンプルで典型的で教科書的なシステムを作ることだ。少なくとも開発の初期段階では、見通しがよく開発と保守がしやすいスキーマを選択すべきで、現状のスキーマはそれに叶うものになっている。時期尚早の最適化をして、人気が出る前に開発が頓挫するというのでは意味がないので、シンプルな構成から始めるというのも重要だ。
Next: STGYのメディアストレージ